AI Docker Framework
April 29, 2023
Overview
Docker framework for running AI projects locally on any platform and easy-install project specific Dockerfiles with dependency issues are pre-patched. Ubuntu OS with NVIDIA CUDA support. Supports the ability run old versions of Python for compatibility with picky projects. A file browser and terminal are exposed as web apps.
Included Containers:
- General AI Project Container
- TorToiSe TTS Fast Voice Cloning Container
- Stable Diffusion Web UI Image Generation Container
- Text Generation Web UI LLM Container
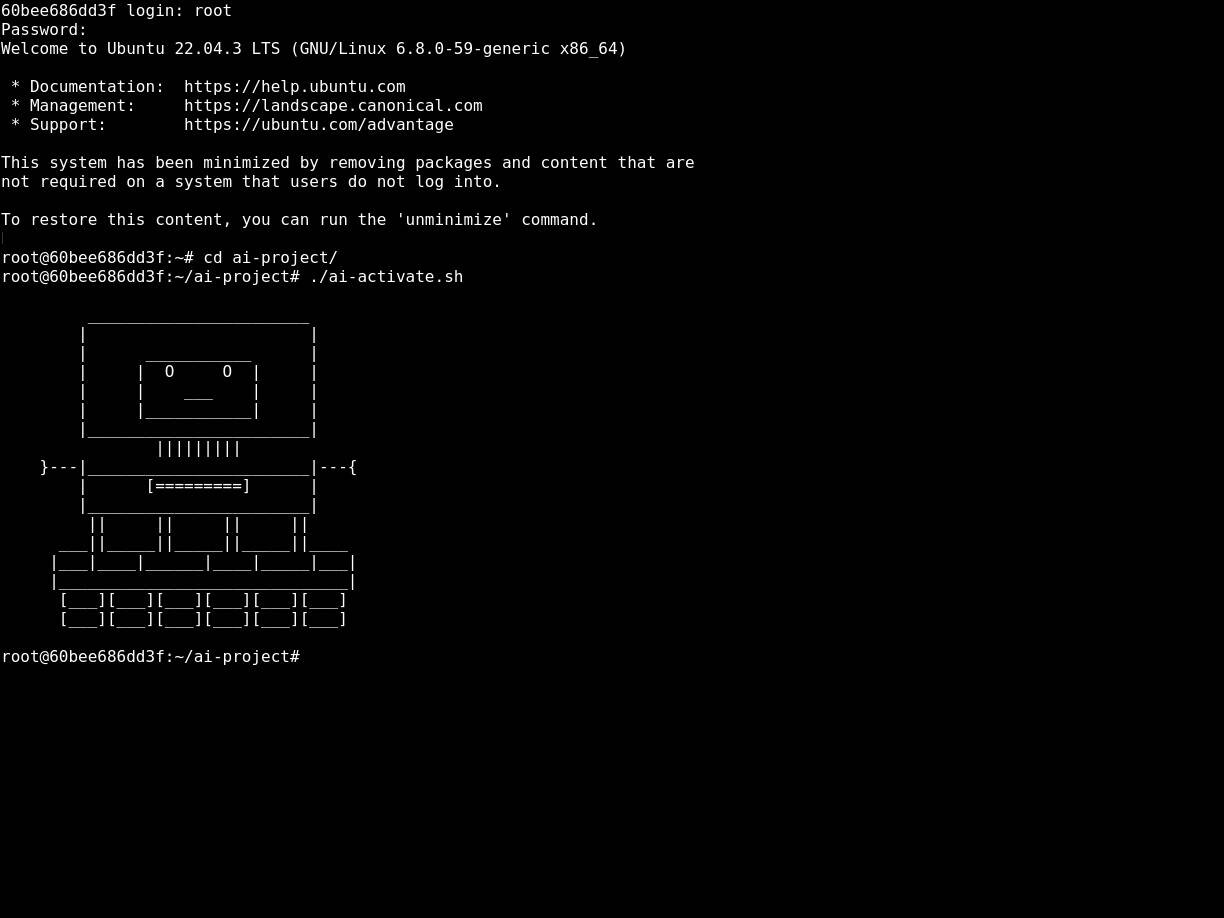
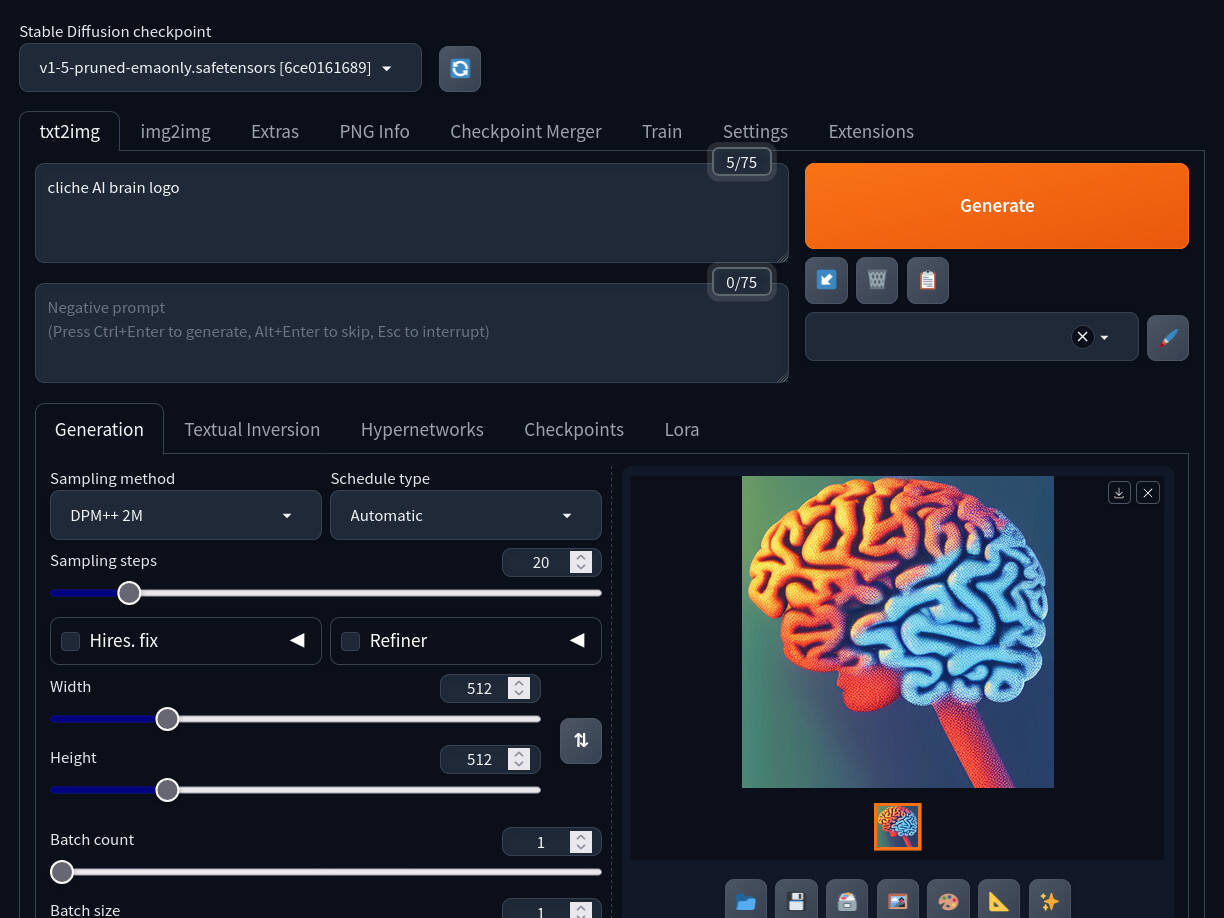
Gallery
Details
After using only a laptop and personal server for many years, I decided to build a desktop computer for the first time in a decade. To minimize latency, I opted for a high-end CPU, the fastest available RAM, and dual SSD's configured in RAID 0 for double the throughput. AI was on my mind, so I bit the bullet and purchased an NVIDIA GeForce RTX 4090 GPU for AI workloads.
Most AI projects are built on Ubuntu. I find Ubuntu to be bloated, so I opted for my own preferred Linux flavor, a lightweight installation of Ubuntu's upstream parent Debian. Even though Ubuntu is based on Debain, I chose to run AI projects in an Ubuntu Docker container to avoid any unexpected compatibility issues and keep the projects contained. Below is the general container framework I built for installing, testing, and running projects. Also included are pre-patched Dockerfiles I created for specific projects that interest me.
These containers are not intended to be exposed directly to the outside web. I use them remotely though a WireGuard VPN. If you want to expose them, follow best practices for security. At a minimum, change all default passwords, specify a Docker user with strict permissions, and consider adding an authentication service like Authentik or Authelia.
General AI Project Container Dockerfile & Usage
This container is a blank slate for spinning up AI projects. It's the foundation for all project specific containers on this page. The container is built for both compatibility and usability. Want to install an old version of Python and experiment with Open AI's Whisper while lying in bed on your smartphone? Go for it!
Features:
- deadsnakes to install old Python versions (edit Dockerfile to preload one)
- Shell In A Box to execute commands via web browser
- File Browser to browse files via web browser
- git, curl, and nano support (absent from NVIDIA Ubuntu images)
General AI Project Container Dockerfile:
FROM nvidia/cuda:12.0.0-devel-ubuntu22.04
# Optional: Change this to your local timezone
ENV TZ=America/Chicago
RUN apt update -y
RUN apt install software-properties-common -y
RUN add-apt-repository ppa:deadsnakes/ppa
RUN apt update -y
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
RUN apt install tzdata -y
# Optional: Install an old version of Python from deadsnakes, e.g. for Whisper AI
# RUN apt install python3.10 -y
RUN apt install python3 -y
RUN apt install python3-pip -y
RUN apt install curl -y
RUN apt install git -y
RUN apt install nano -y
RUN apt install systemd systemd-sysv dbus dbus-user-session -y
# Install ShellInABox
RUN apt install openssl shellinabox -y
RUN apt clean -y
# Install FileBroswer
WORKDIR /root/
RUN curl -fsSL https://raw.githubusercontent.com/filebrowser/get/master/get.sh | bash
# Create startup script to run FileBrowser
WORKDIR /root/
RUN echo '#!/bin/bash\n\n\
# Run File Browser in background & listen on 0.0.0.0:2121\n\
FB_ROOT=/root/ FB_DATABASE=$FB_ROOT/filebrowser.db FB_BASEURL=/filebrowser/ FB_ADDRESS=0.0.0.0 FB_PORT=2121 /usr/local/bin/filebrowser' > /root/startup.sh
RUN chmod +x /root/startup.sh
# Create a system.d service to run /root/startup.sh at boot
RUN echo '[Unit]\n\
Description=Startup Script\n\
After=network.target\n\n\
[Service]\n\
WorkingDirectory=/root\n\
ExecStart=/root/startup.sh\n\
User=root\n\
Restart=on-failure\n\
TimeoutSec=30\n\n\
[Install]\n\
WantedBy=multi-user.target' > /etc/systemd/system/startup.service
RUN systemctl enable startup.service
# AI welcome terminal decoration
RUN echo 'echo' >> /root/.bashrc
RUN echo 'echo -e " _______________________\n | |\n | ___________ |\n | | O O | |\n | | ___ | |\n | |___________| |\n |_______________________|\n |||||||||\n }---|_______________________|---{\n | [=========] |\n |_______________________|\n || || || ||\n ___||_____||_____||_____||____\n |___|____|______|____|_____|___|\n |______________________________|\n [___][___][___][___][___][___]\n [___][___][___][___][___][___]\n"' >> /root/.bashrc
ENTRYPOINT ["/sbin/init"]
RUN echo 'root:password' | chpasswd
# Expose ports for Filebrowser, SellInABox, and Gradio
EXPOSE 2121
EXPOSE 4200
EXPOSE 7860
Save the above as a Dockerfile, then build and run the container:
docker build -t local/ai-test .
docker run --runtime=nvidia --privileged --cap-add=ALL --name ai-test -p 2121:2121 -p 2222:4200 -p 7860:7860 -d local/ai-test
Ports for each service:
- 7860 - Gradio default port
- 2121 - File Browser (user: admin, password: admin)
- 2222 - ShellInABox (requires https, user: root, password: password)
TorToiSe TTS Fast Voice Cloning Dockerfile & Usage
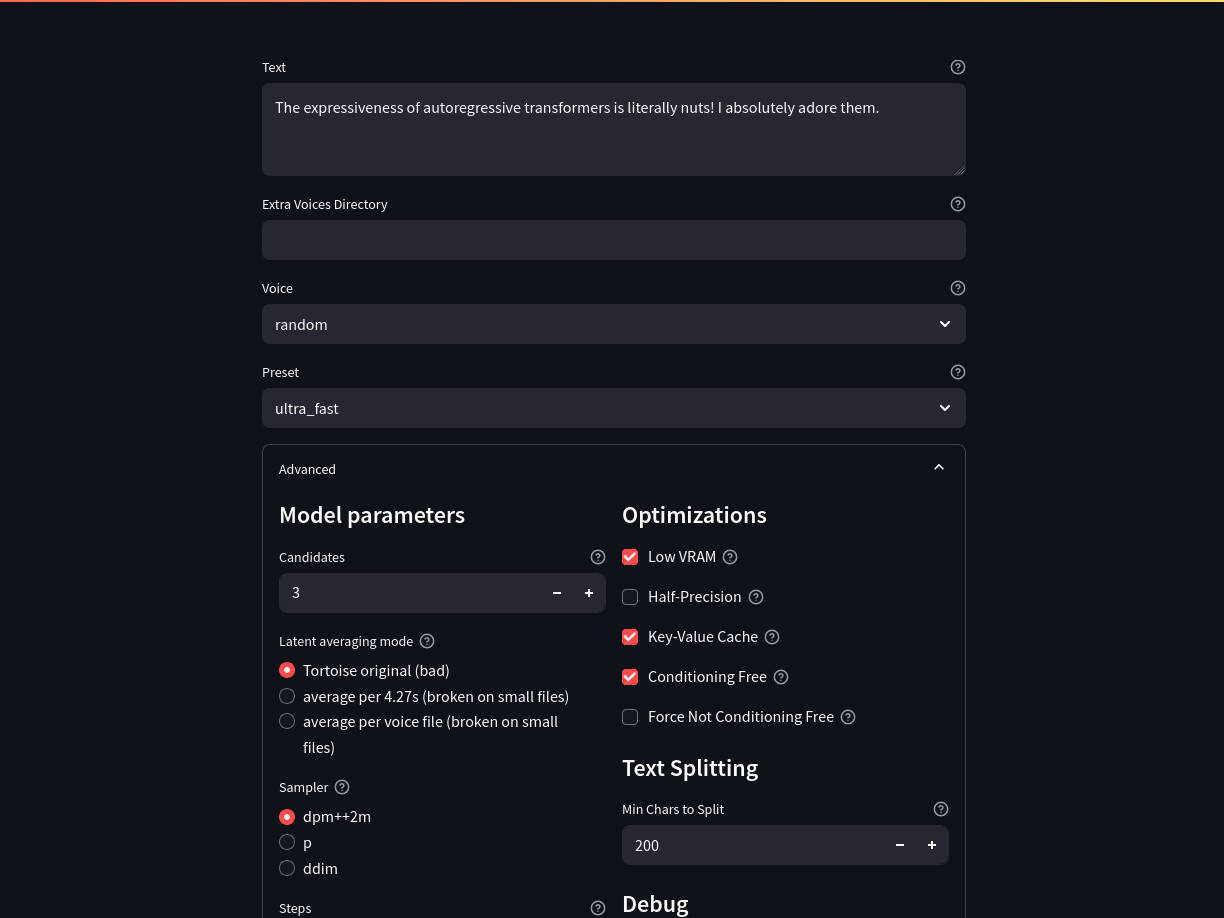
TorToiSe TTS is a multi-voice TTS system trained with an emphasis on quality at the expense of speed. TorToiSe TTS Fast boosts the performance and speed of TorToiSe, without modifying the base models. Inference runs 5-10x faster with added support for BigVGAN, dpm++2m sampling, and CPU offloading.
Requirements for voice samples:
- Clip length target is ~10 seconds
- Use 3-5 clips minimum
- High quality recordings with minimal background noise as the model can sometimes match to room conditions or mic nuances rather than the voice
- Signed 16-bit PCM WAV file format
- Sample rate 20500 Hz (e.g. single mono channel of 44.1 kHz stereo recording)
Command to auto-slice recordings into 10-second clips encoded for use with TorToiSe:
ffmpeg -i "input.wav" -f segment -segment_time 10 -c:a pcm_s16le -ar 22050 -ac 1 -y output/${input[@]/%.ogg/_%03d.wav}
Below is a TorToiSe TTS Fast Dockerfile, which includes fixes for dependency issues and runs the included Streamlit app at startup. You may need to change the PyTorch CUDA version to match your setup by editing the line RUN pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cu118. Change the value of cu118 (CUDA 11.8).
FROM nvidia/cuda:12.0.0-devel-ubuntu22.04
# Optional: Change this to your local timezone
ENV TZ=America/Chicago
RUN apt update -y
RUN apt install software-properties-common -y
RUN add-apt-repository ppa:deadsnakes/ppa
RUN apt update -y
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
RUN apt install tzdata -y
# Optional: Install an old version of Python from deadsnakes, e.g. for Whisper AI
#RUN apt install python3.10 -y
RUN apt install python3 -y
RUN apt install python3-pip -y
RUN apt install curl -y
RUN apt install git -y
RUN apt install nano -y
RUN apt install systemd systemd-sysv dbus dbus-user-session -y
# Install ShellInABox
RUN apt install openssl shellinabox -y
RUN apt clean -y
# Install FileBroswer
WORKDIR /root
RUN curl -fsSL https://raw.githubusercontent.com/filebrowser/get/master/get.sh | bash
# Install TorToiSe TTS Fast
RUN git clone https://github.com/152334H/tortoise-tts-fast
WORKDIR cd /root/tortoise-tts-fast
RUN pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cu128
RUN python3 -m pip install -e /root/tortoise-tts-fast
RUN pip3 install git+https://github.com/152334H/BigVGAN.git
RUN pip3 install streamlit
# Create startup script to run FileBrowser and Gradio app
WORKDIR /root/
RUN echo '#!/bin/bash\n\n\
# Run File Browser in background & listen on 0.0.0.0:2121\n\
FB_ROOT=/root/ FB_DATABASE=$FB_ROOT/filebrowser.db FB_BASEURL=/filebrowser/ FB_ADDRESS=0.0.0.0 FB_PORT=2121 /usr/local/bin/filebrowser & exec </dev/null >/dev/null 2>/dev/null\n\n\
# Run Streamlit app on Gradio default port\n\
streamlit run /root/tortoise-tts-fast/scripts/app.py --server.port 7860' > /root/startup.sh
RUN chmod +x /root/startup.sh
# Create a system.d service to run /root/startup.sh at boot
RUN echo '[Unit]\n\
Description=Startup Script\n\
After=network.target\n\n\
[Service]\n\
WorkingDirectory=/root\n\
ExecStart=/root/startup.sh\n\
User=root\n\
Restart=on-failure\n\
TimeoutSec=30\n\n\
[Install]\n\
WantedBy=multi-user.target' > /etc/systemd/system/startup.service
RUN systemctl enable startup.service
ENTRYPOINT ["/sbin/init"]
RUN echo 'root:password' | chpasswd
# Expose ports for Filebrowser, SellInABox, and Gradio
EXPOSE 2121
EXPOSE 4200
EXPOSE 7860
Save the above as a Dockerfile, then build and run the container:
docker build -t 152334H/tortoise-tts-fast .
docker run --runtime=nvidia --privileged --cap-add=ALL --name tortoise-tts-fast -p 2121:2121 -p 2222:4200 -p 7860:7860 -d 152334H/tortoise-tts-fast
Ports for each service:
- 7860 - TorToiSe TTS Fast Streamlit app
- 2121 - File Browser (user: admin, password: admin)
- 2222 - ShellInABox (requires https, user: root, password: password)
Note: The TorToiSe TTS Fast Streamlit app will take a few minutes to load on first run as all models are downloaded.
Fine tune voices with: https://github.com/152334H/DL-Art-School
StableDiffusion Image Generation Dockerfile & Usage
Stable Diffusion Web UI is feature rich interface for Stable Diffusion, implemented using the Gradio library. The Dockerfile below builds a Stable Diffusion Web UI container, which uses Python 3.11 for project compatibility, fixes dependency issues, and runs the Gradio app at startup with third-party extensions enabled.
FROM nvidia/cuda:12.0.0-devel-ubuntu22.04
# Optional: Change this to your local timezone
ENV TZ=America/Chicago
RUN apt update -y
RUN apt install software-properties-common -y
RUN add-apt-repository ppa:deadsnakes/ppa
RUN apt update -y
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
RUN apt install tzdata -y
# Optional: Install an old version of Python from deadsnakes, e.g. for Whisper AI
RUN apt install python3.11 -y
# RUN apt install python3 -y
RUN apt install python3-pip -y
RUN apt install curl -y
RUN apt install git -y
RUN apt install nano -y
RUN apt install systemd systemd-sysv dbus dbus-user-session -y
# Install ShellInABox
RUN apt install openssl shellinabox -y
# Install FileBroswer
WORKDIR /root
RUN curl -fsSL https://raw.githubusercontent.com/filebrowser/get/master/get.sh | bash
# Install Stable Diffusion Web UI
RUN apt install wget git python3 python3-venv libgl1 libglib2.0-0 ffmpeg libsm6 libxext6 -y
RUN git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
RUN apt clean -y
# Create startup script to run FileBrowser and Gradio app
WORKDIR /root/
RUN echo '#!/bin/bash\n\n\
# Run File Browser in background & listen on 0.0.0.0:2121\n\
FB_ROOT=/root/ FB_DATABASE=$FB_ROOT/filebrowser.db FB_BASEURL=/filebrowser/ FB_ADDRESS=0.0.0.0 FB_PORT=2121 /usr/local/bin/filebrowser & exec </dev/null >/dev/null 2>/dev/null\n\n\
# Listen parameter to listen on 0.0.0.0, no-half parameter for compatibility\n\
bash /root/stable-diffusion-webui/webui.sh -f --listen --no-half --enable-insecure-extension-access' > /root/startup.sh
RUN chmod +x /root/startup.sh
# Create a system.d service to run /root/startup.sh at boot
RUN echo '[Unit]\n\
Description=Startup Script\n\
After=network.target\n\n\
[Service]\n\
WorkingDirectory=/root\n\
ExecStart=/root/startup.sh\n\
User=root\n\
Restart=on-failure\n\
TimeoutSec=30\n\n\
[Install]\n\
WantedBy=multi-user.target' > /etc/systemd/system/startup.service
RUN systemctl enable startup.service
ENTRYPOINT ["/sbin/init"]
RUN echo 'root:password' | chpasswd
# Expose ports for Filebrowser, SellInABox, and Gradio
EXPOSE 2121
EXPOSE 4200
EXPOSE 7860
Save the above as a Dockerfile, then build and run the container:
docker build -t AUTOMATIC1111/stable-diffusion-webui .
docker run --runtime=nvidia --privileged --cap-add=ALL --name stable-diffusion-webui -p 2121:2121 -p 2222:4200 -p 7860:7860 -d AUTOMATIC1111/stable-diffusion-webui
Ports for each service:
- 7860 - Stable Diffusion Web UI
- 2121 - File Browser (user: admin, password: admin)
- 2222 - ShellInABox (requires https, user: root, password: password)
Note: Stable Diffusion Web UI will take a few minutes to load on first run as additional dependencies and models are downloaded.
New models can be added to /root/stable-diffusion-webui/models/Stable-diffusion, e.g. https://huggingface.co/stabilityai/stable-diffusion-2-1/tree/main
Generate vector images for graphic design: https://github.com/GeorgLegato/stable-diffusion-webui-vectorstudio
Text Generation Web UI Dockerfile & Usage
Text Generation Web UI is a Gradio app for running Large Language Models. It supports multiple text generation backends and includes prompt templates that comply with various model prompt formatting structures. The Dockerfile below builds a Text Generation Web UI container and runs the Gradio app at startup with NVIDIA GPU support.
FROM nvidia/cuda:12.0.0-devel-ubuntu22.04
# Optional: Change this to your local timezone
ENV TZ=America/Chicago
RUN apt update -y
RUN apt install software-properties-common -y
RUN add-apt-repository ppa:deadsnakes/ppa
RUN apt update -y
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
RUN apt install tzdata -y
# Optional: Install an old version of Python from deadsnakes, e.g. for Whisper AI
RUN apt install python3.11 -y
# RUN apt install python3 -y
RUN apt install python3-pip -y
RUN apt install curl -y
RUN apt install git -y
RUN apt install nano -y
RUN apt install systemd systemd-sysv dbus dbus-user-session -y
# Install ShellInABox
RUN apt install openssl shellinabox -y
RUN apt clean -y
# Install FileBroswer
WORKDIR /root
RUN curl -fsSL https://raw.githubusercontent.com/filebrowser/get/master/get.sh | bash
# Install Text Generation Web UI
RUN git clone https://github.com/oobabooga/text-generation-webui/
# Run start_linux.sh with user input "A" to configure NVIDIA support
# RUN echo -e "A\n" | /root/text-generation-webui/start_linux.sh >/dev/null
# Create startup script to run FileBrowser and Gradio app
WORKDIR /root/
RUN echo '#!/bin/bash\n\n\
# Run File Browser in background & listen on 0.0.0.0:2121\n\
FB_ROOT=/root/ FB_DATABASE=$FB_ROOT/filebrowser.db FB_BASEURL=/filebrowser/ FB_ADDRESS=0.0.0.0 FB_PORT=2121 /usr/local/bin/filebrowser & exec </dev/null >/dev/null 2>/dev/null\n\n\
# Listen parameter to listen on 0.0.0.0\n\
# Pass user input "A" to configure NVIDIA support on first run
echo -e "A\n" | /root/text-generation-webui/start_linux.sh --listen' > /root/startup.sh
RUN chmod +x /root/startup.sh
# Create a system.d service to run /root/startup.sh at boot
RUN echo '[Unit]\n\
Description=Startup Script\n\
After=network.target\n\n\
[Service]\n\
WorkingDirectory=/root\n\
ExecStart=/root/startup.sh\n\
User=root\n\
Restart=on-failure\n\
TimeoutSec=30\n\n\
[Install]\n\
WantedBy=multi-user.target' > /etc/systemd/system/startup.service
RUN systemctl enable startup.service
ENTRYPOINT ["/sbin/init"]
RUN echo 'root:password' | chpasswd
# Expose ports for Filebrowser, SellInABox, and Gradio
EXPOSE 2121
EXPOSE 4200
EXPOSE 7860
Save the above as a Dockerfile, then build and run the container:
docker build -t oobabooga/text-generation-webui .
docker run --runtime=nvidia --privileged --cap-add=ALL --name text-generation-webui -p 2121:2121 -p 2222:4200 -p 7860:7860 -d oobabooga/text-generation-webui
Ports for each service:
- 7860 - Text Generation Web UI
- 2121 - File Browser (user: admin, password: admin)
- 2222 - ShellInABox (requires https, user: root, password: password)
Note: Text Generation Web UI will take a few minutes to load on first run as NVIDIA support is configured and additional dependencies are installed.
MaskGCT Voice Cloning Dockerfile & Usage
MaskGCT is a high quality, consistent, and easy to use tool for voice cloning. It requires very short audio clips and performs best with clips in the 5 to 10 sec range. Longer clips are worse, surprisingly. I use voice samples with a diverse set of phonemes and voice intonation that matches my desired output. MaskGCT is not picky about background noise, stereo WAV files, or WAV file sample rates like TorToiSe TTS.
The build instructions on GitHub have broken dependencies. Below is a working Dockerfile, which includes fixes for those dependencies automatically runs the MaskGCT Gradio app at startup.
FROM nvidia/cuda:12.0.0-devel-ubuntu22.04
# Optional: Change this to your local timezone
ENV TZ=America/Chicago
RUN apt update -y
RUN apt install software-properties-common -y
RUN add-apt-repository ppa:deadsnakes/ppa
RUN apt update -y
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
RUN apt install tzdata -y
# Optional: Install an old version of Python from deadsnakes, e.g. for Whisper AI
RUN apt install python3.10 -y
# RUN apt install python3 -y
RUN apt install python3-pip -y
RUN apt install curl -y
RUN apt install git -y
RUN apt install nano -y
RUN apt install systemd systemd-sysv dbus dbus-user-session -y
# Install ShellInABox
RUN apt install openssl shellinabox -y
# Install FileBroswer
WORKDIR /root
RUN curl -fsSL https://raw.githubusercontent.com/filebrowser/get/master/get.sh | bash
# Install MaskGCT system dependencies and clean up apt cache
RUN apt-get install espeak-ng cmake ffmpeg -y
RUN apt-get clean -y
# Clone Amphion repository with sparse-checkout for MaskGCT
RUN git clone --no-checkout --filter=blob:none https://github.com/open-mmlab/Amphion.git
WORKDIR /root/Amphion
RUN git sparse-checkout init --cone
RUN git sparse-checkout set models/tts/maskgct
RUN git checkout main
RUN git sparse-checkout add models/codec utils
# Fix broken Python dependencies & install requirements
RUN pip install numpy
RUN pip install git+https://github.com/chameleon-ai/LangSegment-0.3.5-backup.git
RUN pip install pyopenjtalk==0.3.4
RUN pip install --no-build-isolation openai-whisper
RUN pip install --no-cache-dir -r models/tts/maskgct/requirements.txt
# Modify Gradio launch configuration to listen on 0.0.0.0
RUN sed -i 's/iface\.launch(allowed_paths=\["\.\/output"\])/iface.launch(allowed_paths=\["\.\/output"\],server_name="0.0.0.0")/' models/tts/maskgct/gradio_demo.py
# Create startup script to run FileBrowser and Gradio demo
WORKDIR /root/
RUN echo '#!/bin/bash\n\n\
# Run File Browser in background & listen on 0.0.0.0:2121\n\
FB_ROOT=/root/ FB_DATABASE=$FB_ROOT/filebrowser.db FB_BASEURL=/filebrowser/ FB_ADDRESS=0.0.0.0 FB_PORT=2121 /usr/local/bin/filebrowser & exec </dev/null >/dev/null 2>/dev/null\n\n\
# Run MaskGCT gradio web UI and API\n\
cd /root/Amphion/\n\
python3 -m models.tts.maskgct.gradio_demo' > /root/startup.sh
RUN chmod +x /root/startup.sh
# Create a system.d service to run /root/startup.sh at boot
RUN echo '[Unit]\n\
Description=Startup Script\n\
After=network.target\n\n\
[Service]\n\
WorkingDirectory=/root\n\
ExecStart=/root/startup.sh\n\
User=root\n\
Restart=on-failure\n\
TimeoutSec=30\n\n\
[Install]\n\
WantedBy=multi-user.target' > /etc/systemd/system/startup.service
RUN systemctl enable startup.service
ENTRYPOINT ["/sbin/init"]
RUN echo 'root:password' | chpasswd
# Expose ports for Filebrowser, SellInABox, and Gradio
EXPOSE 2121
EXPOSE 4200
EXPOSE 7860
Save the above as a Dockerfile, then build and run the container:
docker build -t Amphion/mask-gct .
docker run --runtime=nvidia --privileged --cap-add=ALL --name mask-gct -p 2121:2121 -p 2222:4200 -p 7860:7860 -d Amphion/mask-gct
Ports for each service:
- 7860 - MaskGCT Gradio app
- 2121 - File Browser (user: admin, password: admin)
- 2222 - ShellInABox (requires https, user: root, password: password)
Note: The MaskGCT Gradio app will take a few minutes to load on first run as all models are downloaded.
License: CC BY-SA 4.0 Deed - You may copy, adapt, and use this work for any purpose, even commercial, but only if derivative works are distributed under the same license.
Category: Software